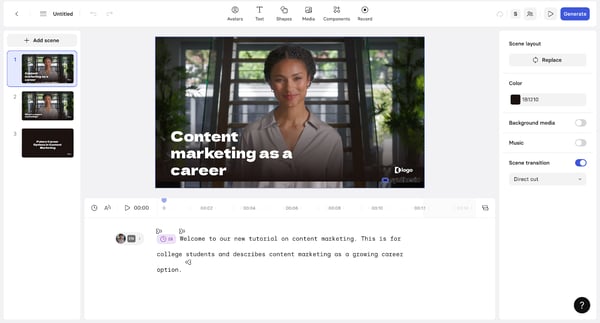
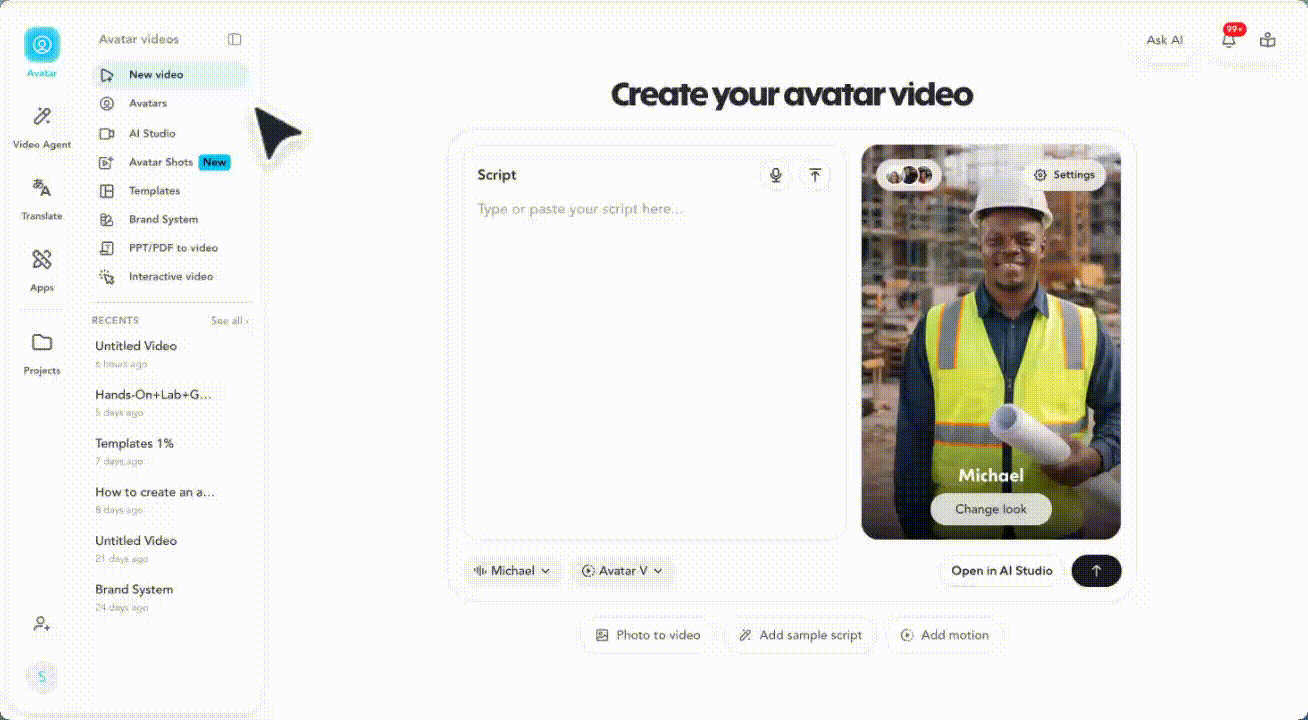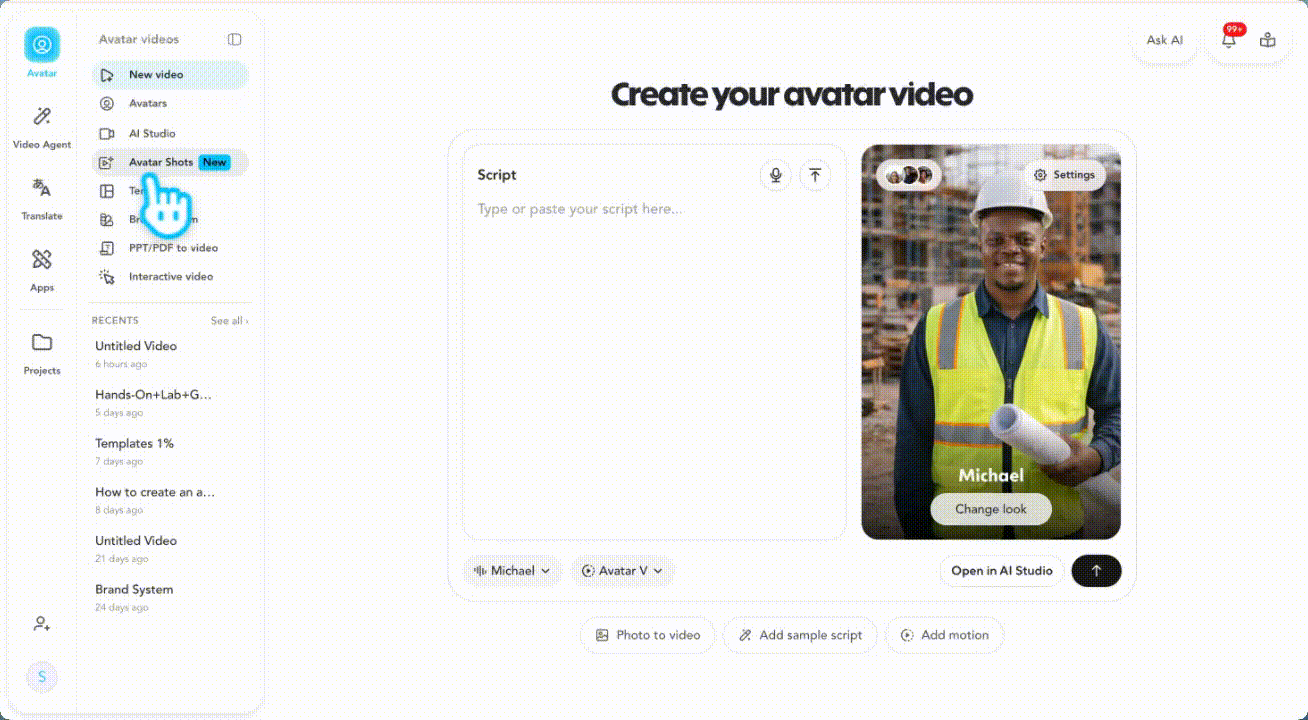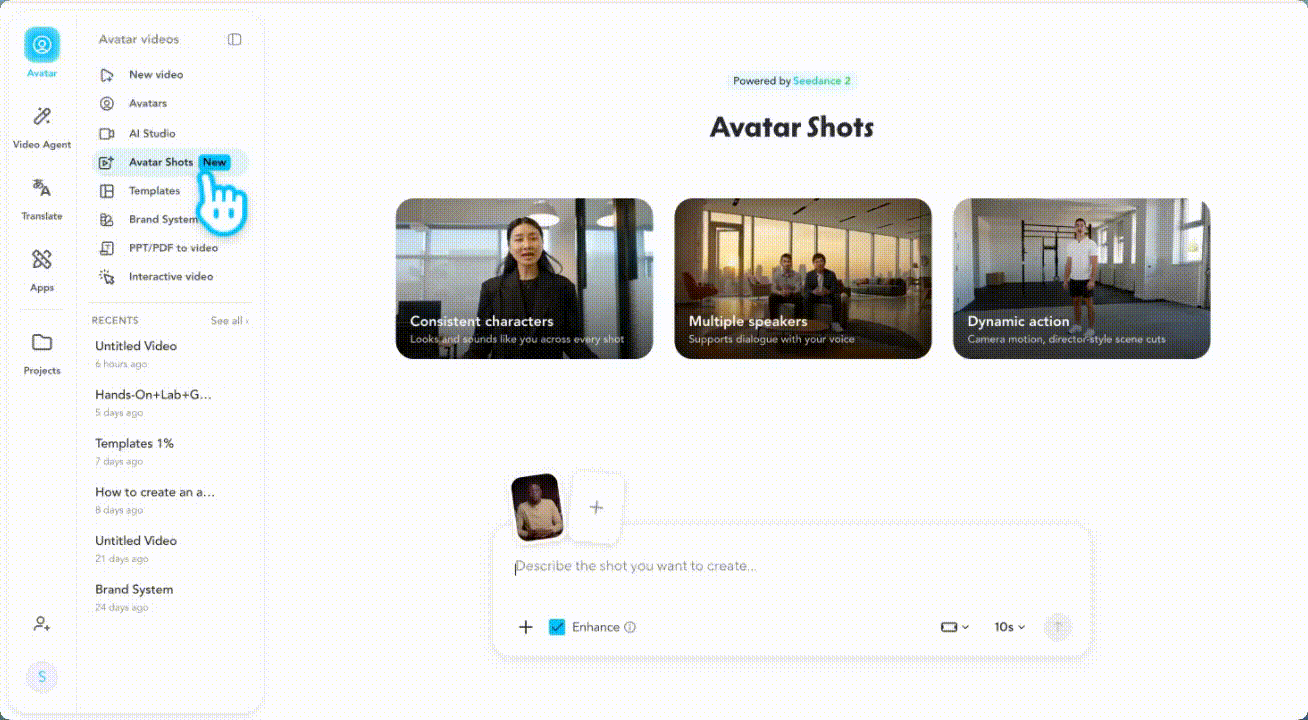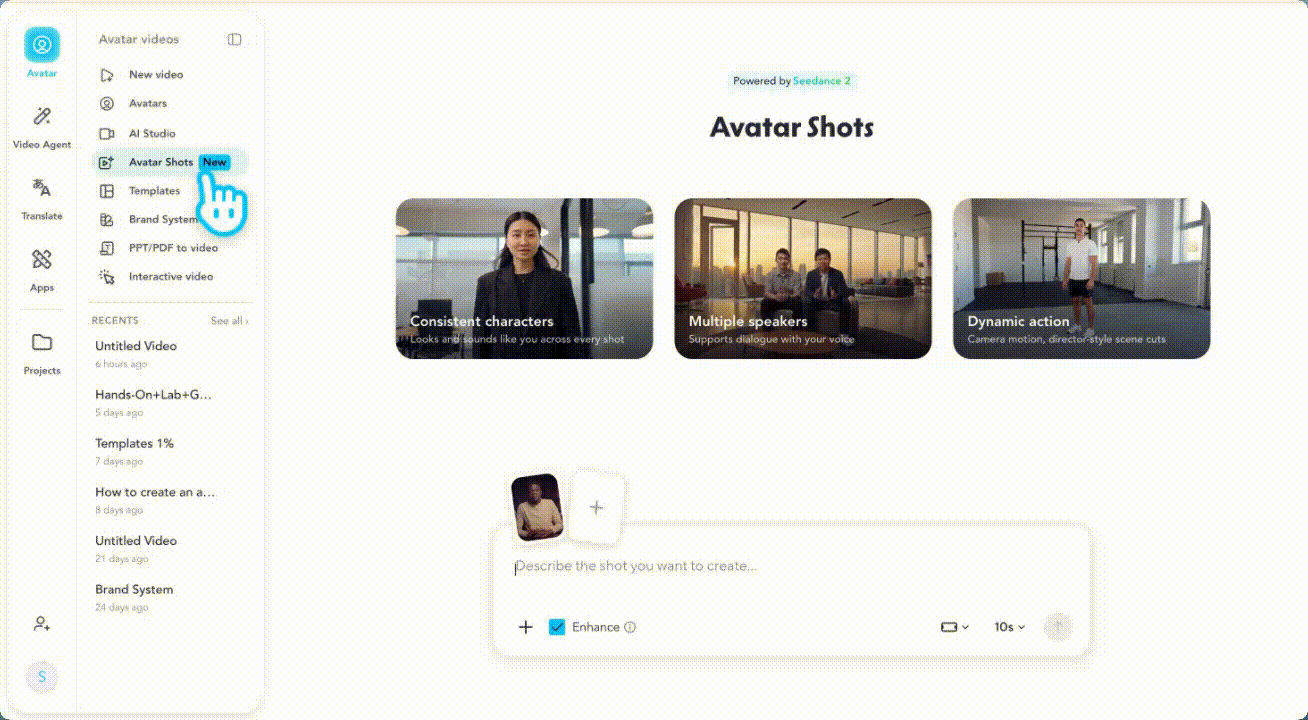
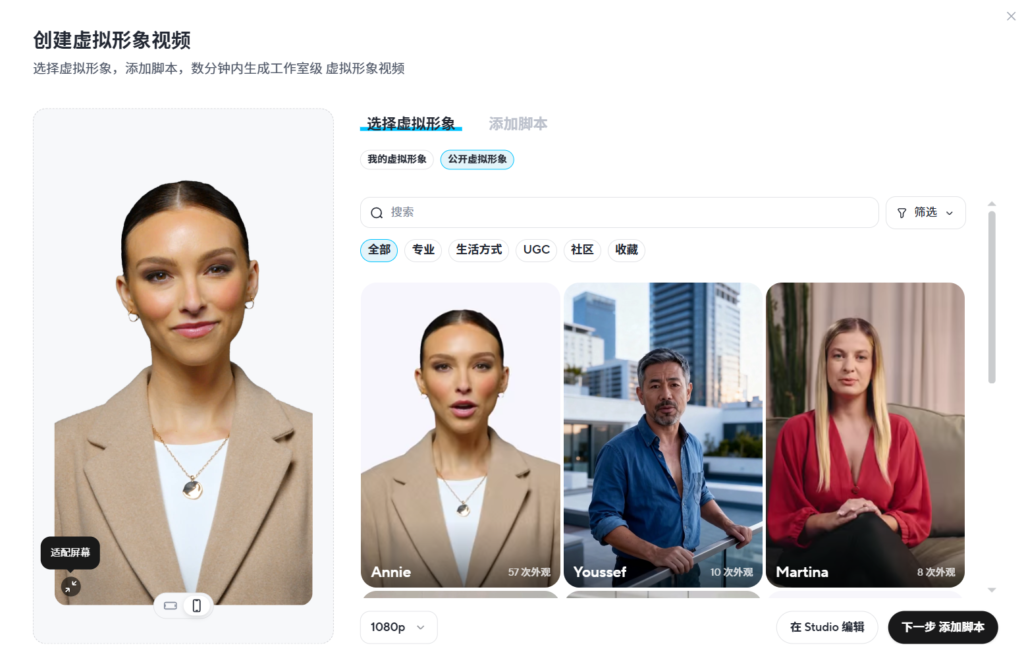
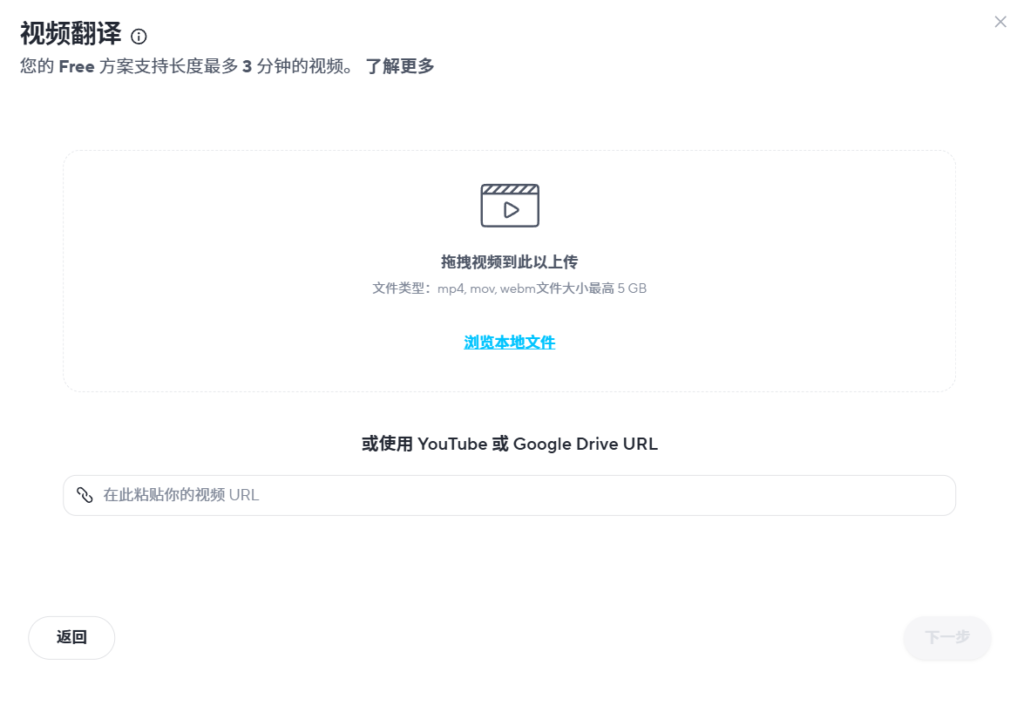
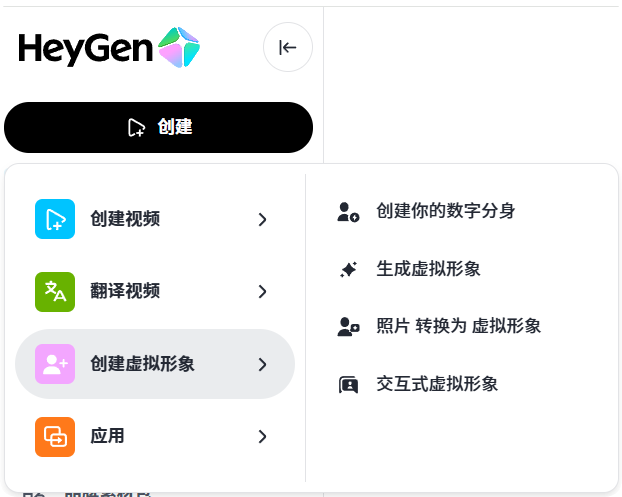
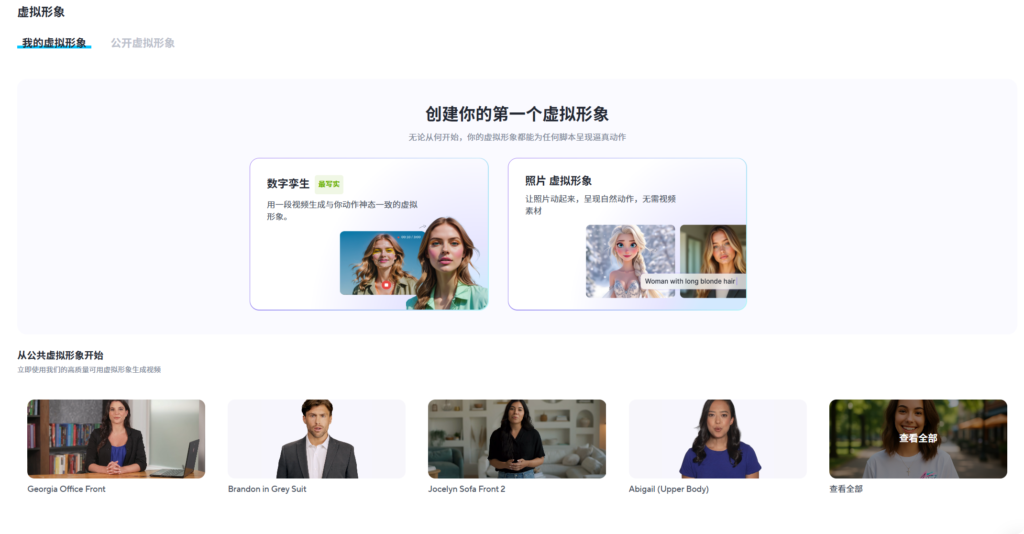
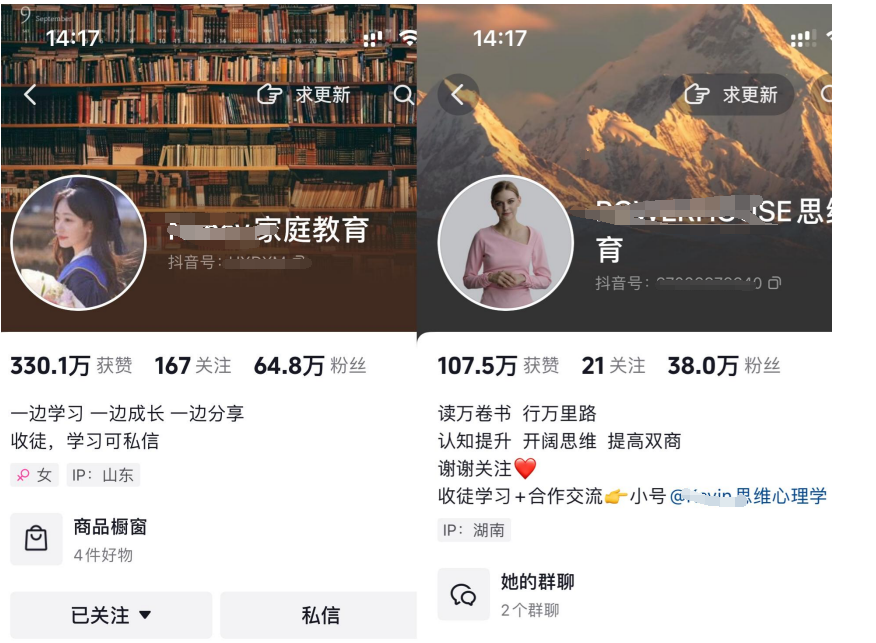
Avatar Shots 由 Seedance 提供技术支持,它对详尽的电影化提示反应尤为灵敏。与其他只需简单描述即可的工具不同,Avatar Shots 鼓励您像导演一样思考。您的提示越具体、结构越清晰,最终效果就越好。由于每次生成都使用不可撤销的积分,因此精心设计的提示绝对值得您花费额外的时间。
刚开始使用 Avatar Shots?请先阅读“如何使用 Avatar Shots 创建视频”指南,然后再回到这里提升您的提示级别。
本指南涵盖哪些内容
- 核心提示原则
- 如何描述镜头运动
- 如何使用脚本和旁白
- 如何制作多镜头视频
- 如何使用引用元素
- 如何通过多个镜头拍摄更长的视频
- 语言提示技巧
核心提示原则
以镜头为单位思考,而不是以句子为单位思考。
像绘制故事板一样组织你的场景,而不是用文字描述。Seedance 对多镜头提示的处理非常出色。不要直接写下你想发生的事情,而是把它描述成一系列镜头。
✅ “从两位主持人的广角镜头开始 → 切换到左侧主持人的特写 → 拉远镜头,展现完整场景。”
大胆而具体地描述。
通用的提示语只能制作出通用的视频。而像“透过百叶窗的金色阳光”、“空气中的灰尘颗粒”或“慢动作的闪电”这样的具体细节,会对最终的成片效果产生真正的影响。
说出这种氛围
添加风格参考有助于确定视觉基调。可以尝试使用“电影感”、“胶片级”、“音乐视频风格”、“纪录片风格”、“动漫美学”或“商业产品拍摄”等词语。
生成前先做好计划
由于每次生成都会消耗积分且无法撤销,因此在点击生成之前,请务必花时间完善您的提示。您的提示越完善,所需的尝试次数就越少。有关更多详细信息,请参阅
积分消耗明细。
描述摄像机运动
Seedance 严格遵循电影镜头语言。使用特定的术语可以精确地获得你想要的运动效果。
| 你想要什么 | 如何提示它 |
|---|---|
| 镜头拉近 | “慢推入” / “慢推近至特写” |
| 镜头拉远 | “推拉” / “拉开露出” |
| 俯视镜头 | “吊臂俯瞰” |
| 摄像机跟随运动 | “从右侧拍摄的跟踪镜头” |
| 广角场景镜头 | “广角镜头向右摇摄” |
| 静止的特写 | “中景镜头——静止,面向镜头” |
脚本与旁白,了解它们的区别
关键区别在于你的虚拟形象的嘴部是否在说话。切勿在同一提示中混用这两种情况,否则可能无法正常显示。当您的虚拟形象需要直接向摄像头传递信息并实现可见的唇形同步时,请使用脚本。
提示:一个着装专业的虚拟人物坐在现代化的办公室里。镜头缓慢推进。脚本:“如今的成功在于清晰的思路、快速的行动和高效的执行。正确的思维方式和合适的工具,决定成败。”
当您想要营造电影般的动作效果而又不想听到直接的对话时,可以使用旁白功能。此时,您的虚拟形象会移动、做出反应或进行表演,同时旁白会在画面上播放。
提示:一个虚拟人物开始写笔记,然后站起身走向附近的窗户。旁白:“如今的成功在于清晰的思路、快速的行动和高效的执行。正确的思维方式和合适的工具,决定成败。”
音频描述
由于您无法上传音频文件,请直接在提示中描述您希望音频听起来是什么样子。Seedance 会自动生成音频。
- “咖啡馆环境音效”
- “电影般的管弦乐渐强”
- “欢快的低保真音乐”
- “气势恢宏的管弦乐配乐逐渐推向高潮”
- “远处传来的城市环境音效和交通声”
提示:如果您需要在生成后完全控制音频,请将您的 Avatar Shots 片段导入HeyGen AI Studio,添加您自己的音乐或音效。
一代人就能制作多镜头视频
Seedance支持在单个提示中拍摄多个镜头。您可以为每个镜头定义不同的拍摄角度、运动和时间,同时保持您的虚拟形象、环境和身份在所有镜头中保持一致。
使用时间戳清晰地定义每个镜头,并在顶部描述一次环境,以便所有镜头保持一致。
示例提示:
一个穿着职业装的虚拟人物身处干净现代的办公环境中,办公室里有一张办公桌,柔和的自然窗光在整个场景中清晰可见。
[0-5秒]:正面视角——中景,略微推近。虚拟人物面向镜头,开始说话:“但是如何将想法变成现实呢?”
[5秒-10秒]:侧面轮廓——中景。镜头切换到清晰的侧面角度,虚拟人物继续说道:“这需要专注……和合适的工具。”
[10秒-15秒]:广角镜头——推拉镜头。镜头拉远,展现出更多的工作区域,同时虚拟人物说道:“因为执行力才是真正决定成败的关键。”
电影级4K画质,浅景深,柔和的自然光线,细腻的胶片颗粒感。角度过渡平滑,构图稳定,镜头风格一致,口型同步精准,无失真。
使用参考元素
每代最多可上传 3 张参考图片,用于指导视频内容的制作。元素不能包含人脸,支持的类型包括产品、环境、服装和类似的非人类资产。
| 目标 | 如何使用元素 |
|---|---|
| 阿凡达穿着特定的服装 | 将服装图片作为元素上传。 |
| 所有镜头背景保持一致。 | 上传一张环境照片作为元素 |
| 虚拟形象持有或与产品互动 | 上传产品图片并引发互动 |
| 符合特定的视觉风格或氛围 | 上传一张符合您想要的配色方案或美学风格的参考图片。 |
使用所有三个元素(头像+产品+环境)的示例提示:
一个虚拟人物身着粉彩色系服装,手持 HeyGen 马克杯,在现代办公环境中面向镜头,自信而充满活力地交谈。虚拟人物自然地融入所有元素——轻柔地挥动马克杯,保持着凸显服装的姿态,并在工作空间中自然地互动。构图清晰明了,所有元素一目了然。镜头缓慢推进。电影级 4K 分辨率,浅景深,柔和均衡的光线,以及胶片颗粒感。
脚本:“好的工具、好的风格和合适的环境,一切都相辅相成。这就是如何更快、更智能、更出色地进行创作。”
参考照片:

结果视频:

通过多个镜头制作更长的视频
由于每一代最长为 15 秒,因此较长的视频需要在HeyGen AI Studio中将多个单独的生成版本拼接在一起。
为了保持镜头间画面的一致性:
- 在每一代作品中,都将相同的服装元素添加到作品中。
- 在每一代中添加相同的环境引用作为元素
- 在每个提示中,保持风格描述(光线、相机质量、胶片颗粒)一致
例如,一段分为两部分的播客对话:
场景一提示:
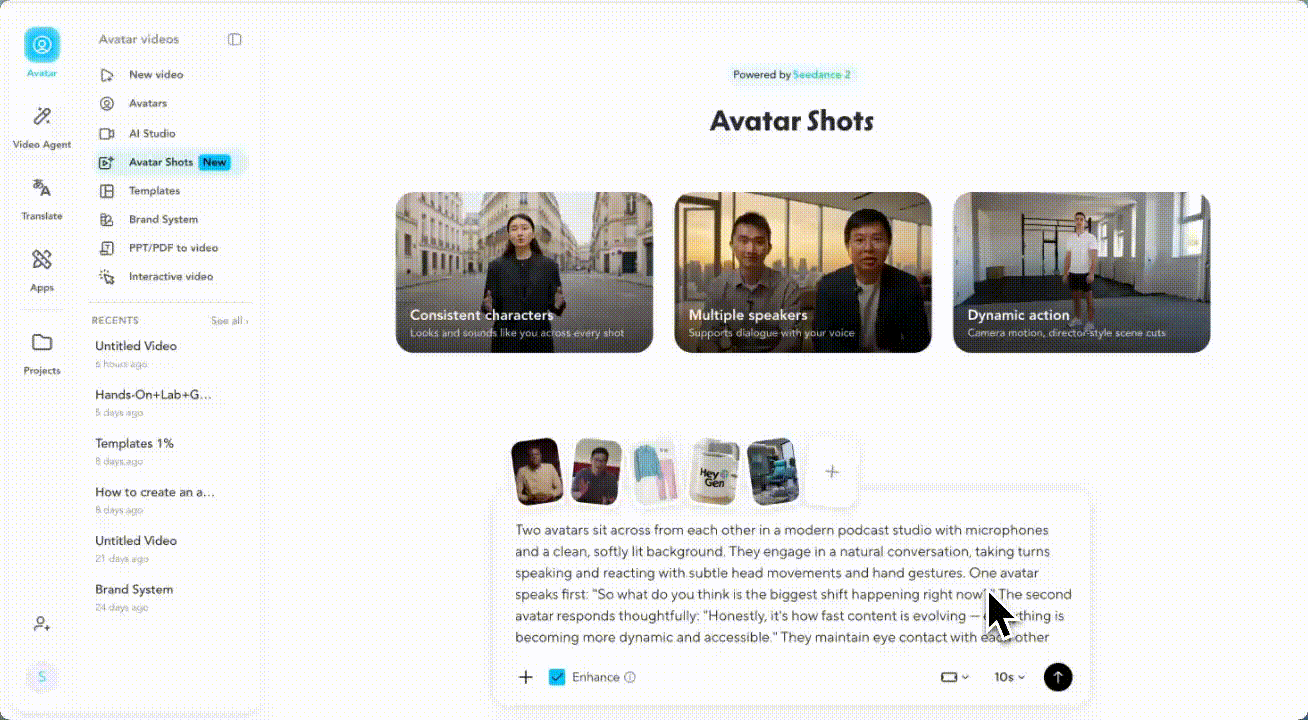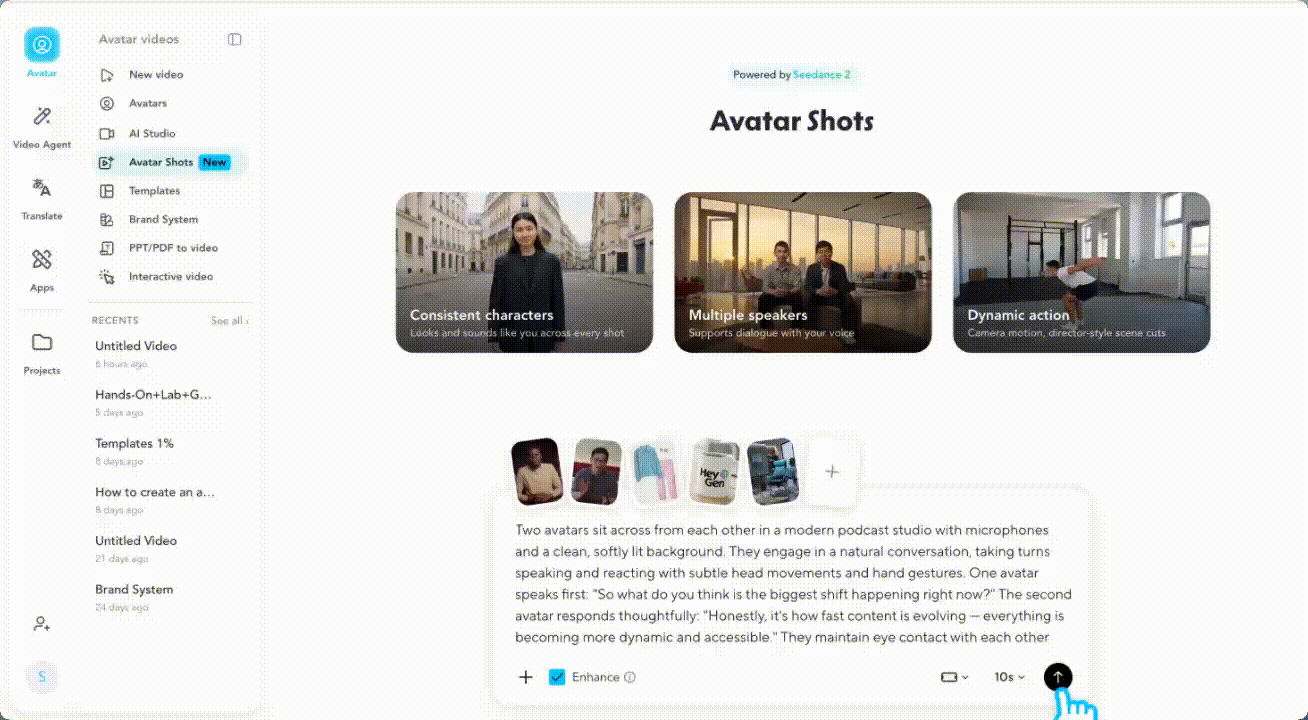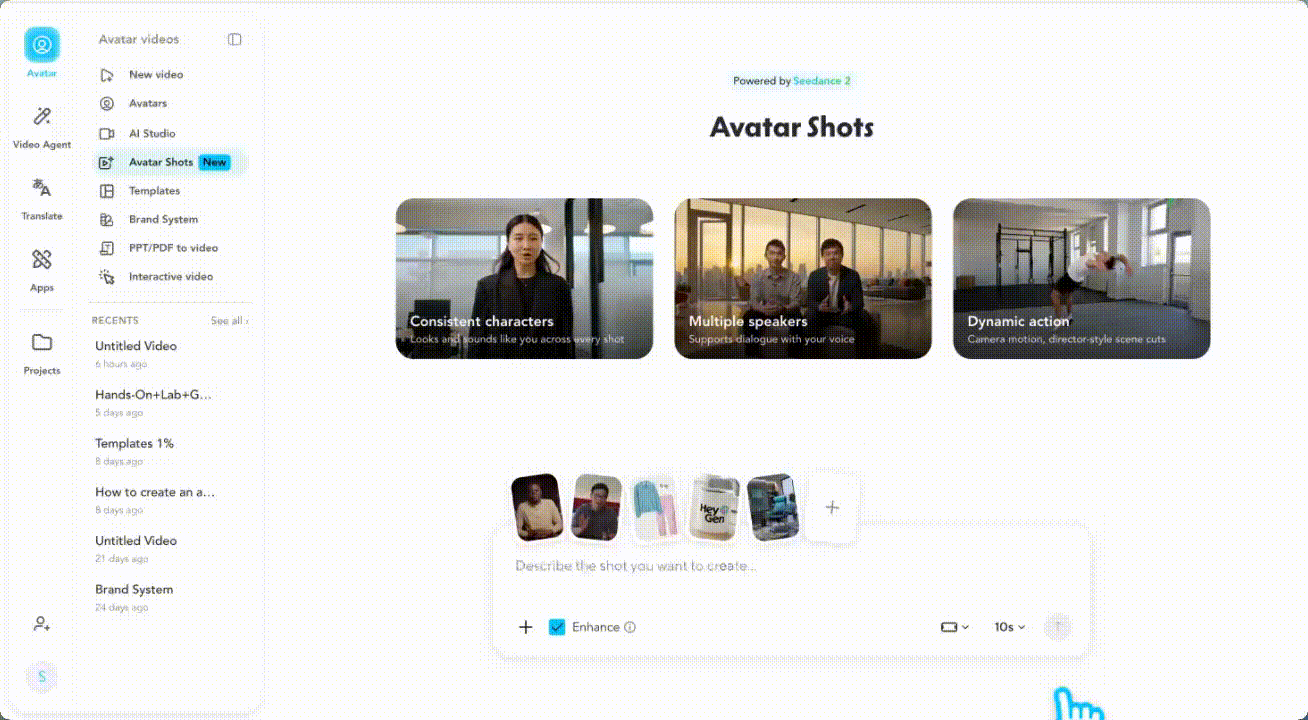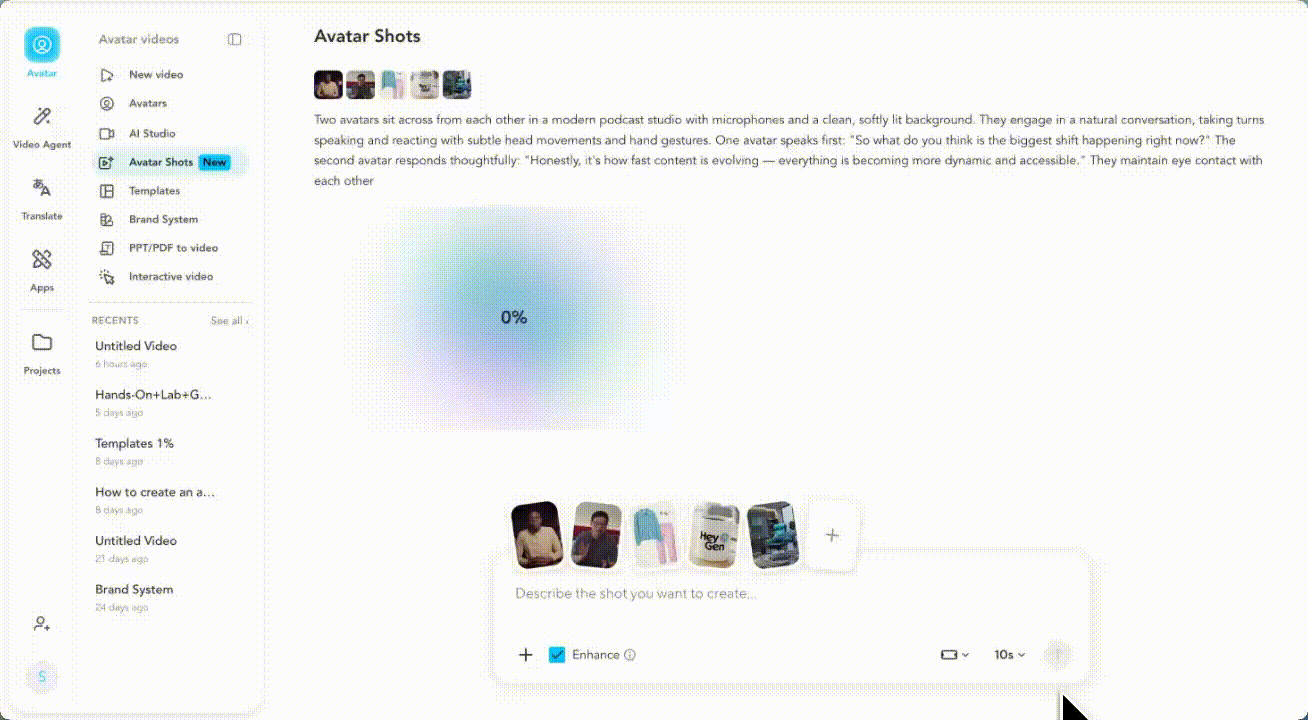
两个虚拟化身在现代化的播客工作室里相对而坐,麦克风和柔和干净的背景灯光映衬着他们。他们进行着自然的对话,轮流发言,并用细微的头部动作和手势做出回应。其中一个虚拟化身先开口:“你觉得现在最大的变化是什么?” 第二个虚拟化身若有所思地回答:“说实话,是内容发展的速度——一切都变得更加动态,也更容易获取。” 他们始终保持着眼神交流。

场景 2 提示(延续上一场景):
第一个虚拟形象点点头,接着说:“是啊,感觉现在每个人都被期望去创造,而不仅仅是消费。”第二个虚拟形象微微前倾,回答道:“没错——而且准入门槛基本上消失了。任何人只要有想法就能把它变成现实。”
多头像提示
当在同一场景中放置多个虚拟形象时,要明确说明它们如何相互互动以及每个虚拟形象会说什么。
三个化身可以在同一场景中说话。
虚拟化身可以彼此互动和做出反应每个虚拟化身都使用与其自身数字克隆体连接的声音。
多头像提示的技巧:
给每个头像清楚地贴上标签,例如“第一个头像”、“左边的头像”。
描述他们的相对位置,“面对面坐着”、“并排站着”。
描述反应,而不仅仅是言语,“第二个化身向前倾身并回答”
语言提示技巧
Seedance 官方支持英语、普通话(包括粤语)、日语、韩语、西班牙语、法语、德语和葡萄牙语。
您还可以在同一提示中混合使用最多2 种受支持的语言
,让您的头像在单个场景中切换语言。
例如,双语场景:
中景镜头——静止画面。虚拟人物坐着,面向镜头。语气友善,如同老师一般。手势轻柔。
阿凡达(英语):“让我们学习一个简单的西班牙语短语。” (短暂的停顿,微笑)阿凡达(西班牙语):“La comunicación es clave。” (短暂停顿)阿凡达(英语):“这意味着:沟通是关键。” (鼓励的语气)阿凡达(西班牙语,较慢的发音):“La…comunicación…esclave。”
提示:如果您的语言不在支持列表中,请先生成英文视频,然后使用 HeyGen 的翻译功能进行转换。
生成前的质量检查清单
点击生成之前,请先查看以下列表:
- 我描述过场景、氛围和光线吗?
- 我是否指定了摄像机运动?
- 我描述清楚我想要的音频了吗?
- 我使用的是脚本还是配音(两者不可兼得)?
- 我是否根据需要添加了产品、服装或环境的元素引用
- 如果使用多张照片,我是否定义了时间戳?